Configuration#
Usage#
Let’s assume you started a new project and created a jupyter notebook
%ls
config_docs.ipynb
Initialize a new project#
The recommended way is to import the CONFIG and initialize a new project. However this isn’t required just recommended.
from pyglotaran_extras import CONFIG
CONFIG.init_project()
plotting:
general:
default_args_override:
linlog: true
use_svd_number: true
linthresh: 2
axis_label_override:
time: Time (ps)
spectral: Wavelength (nm)
data_left_singular_vectors: ''
data_singular_values: Singular Value (a.u.)
data_right_singular_vectors: ''
plot_svd:
default_args_override:
use_svd_number: false
plot_overview:
default_args_override:
show_data: true
This will look up all config files in your home folder, the notebook folders parent folder, and the notebook folder, combine them and create a new config and schema file in the notebook folder for you, as well as rediscovering and reloading the config (see file-lookup).
Note
If a config file already exists, the file creation will be skipped in order to not overwrite an exported custom schema with your own plot functions.
Tip
If you don’t want the config to be shown in the cell output, just add a ; after CONFIG.init_project().
%ls
config_docs.ipynb pygta_config.schema.json pygta_config.yml
Discovering and loading config files#
If you want to only work with one config file you can simply load it.
CONFIG.load("../fs_config.yml")
plotting:
general:
axis_label_override:
time: Time (fs)
If you don’t like the way config files are looked up you can manually rediscover them and reload the config.
Note
Note that the reload is only used for demonstration purposes, since the config is autoreloaded before being used (see auto-reload)
CONFIG.rediscover(include_home_dir=False, lookup_depth=3)
CONFIG.reload()
plotting:
general:
default_args_override:
linlog: true
use_svd_number: true
linthresh: 2
axis_label_override:
time: Time (ps)
spectral: Wavelength (nm)
data_left_singular_vectors: ''
data_singular_values: Singular Value (a.u.)
data_right_singular_vectors: ''
plot_svd:
default_args_override:
use_svd_number: false
plot_overview:
default_args_override:
show_data: true
How the config affects plotting#
To demonstrate the difference between not using the config and using the config we create a copy of our project_config as well as an empty_config (same as not having a config at all).
from pyglotaran_extras.config.config import Config
project_config = CONFIG.model_copy(deep=True)
empty_config = Config()
Default plotting behavior#
By default plots don’t do renaming to make it easier to find the underlying data in the dataset.
from glotaran.testing.simulated_data.parallel_spectral_decay import DATASET
from pyglotaran_extras import plot_data_overview
CONFIG._reset(empty_config)
plot_data_overview(DATASET);
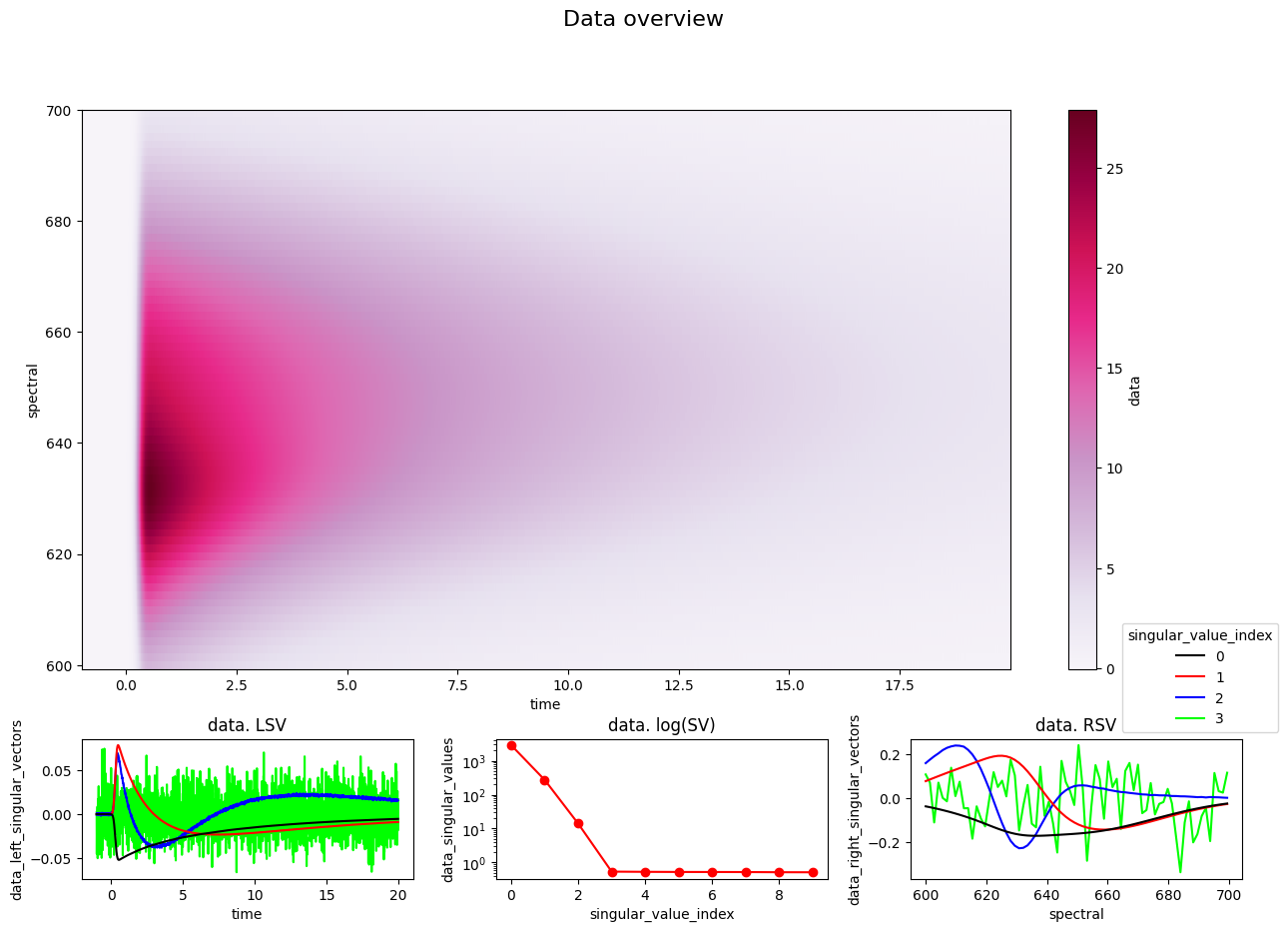
Manually adjusting the Plot#
So in order to make you plots ready for a publication you have to set all the labels and add plot function arguments each time you call it, and keeping things in sync for all plots you generate.
fig, axes = plot_data_overview(DATASET, linlog=True, linthresh=2, use_svd_number=True)
axes[0].set_xlabel("Time (ps)")
axes[0].set_ylabel("Wavelength (nm)")
axes[1].set_xlabel("Time (ps)")
axes[1].set_ylabel("")
axes[2].set_ylabel("Singular Value (a.u.)")
axes[3].set_xlabel("Wavelength (nm)")
axes[3].set_ylabel("");
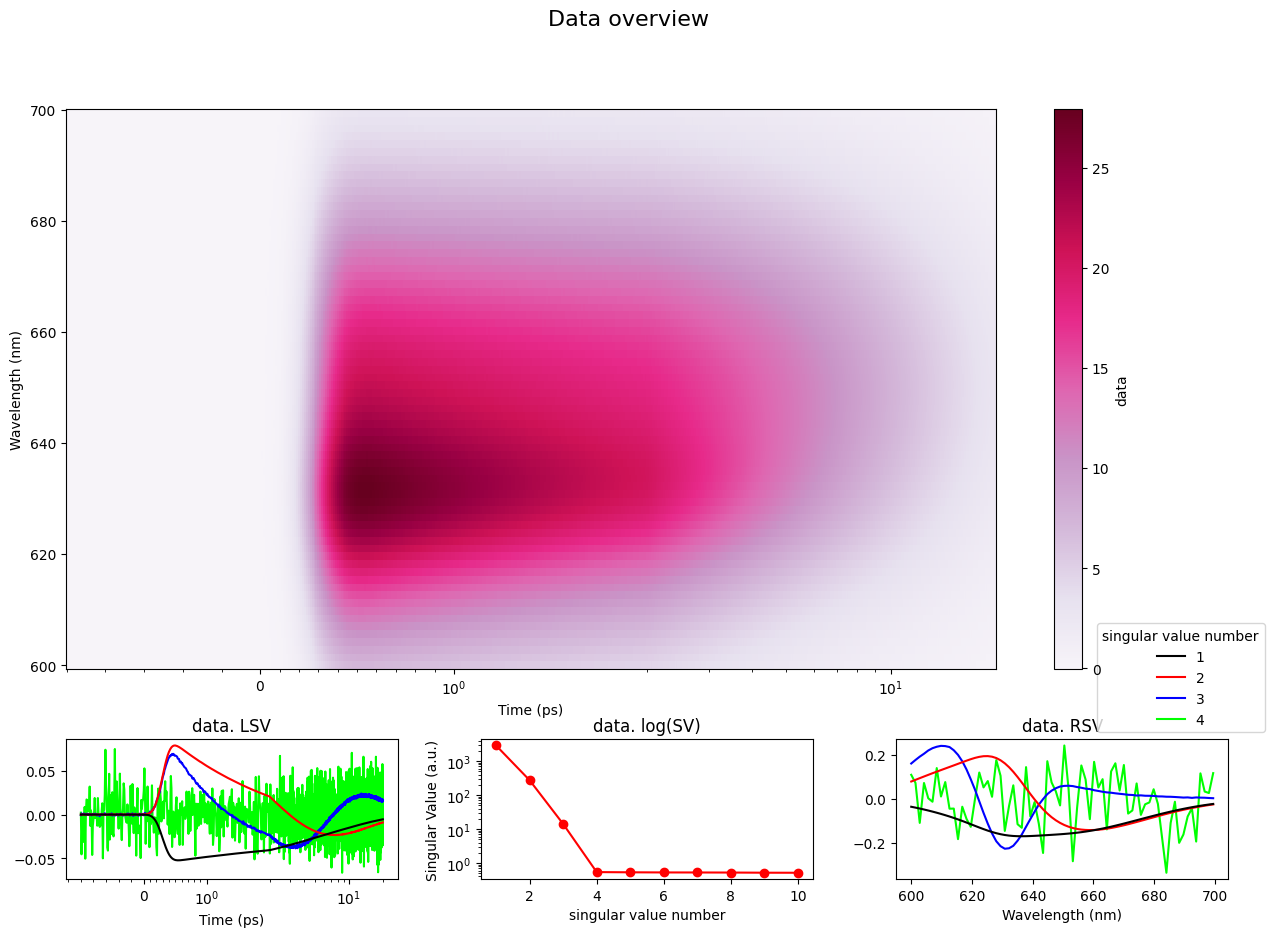
Using the plot config#
The same as with manually changing your plots and function arguments can be achieved with plot config, but it is way less code, keeps all plots in sync for you and spares you from copy pasting the same things all over the place.
CONFIG._reset(project_config)
plot_data_overview(DATASET);
Temporarily changing the config#
Let’s assume that one dataset uses wavenumbers instead of wavelength as spectral axis.
You can simply define a PerFunctionPlotConfig and call your plot function inside of a plot_config_context.
This way you can even override function specific configuration defined in your config file.
from pyglotaran_extras import PerFunctionPlotConfig
from pyglotaran_extras import plot_config_context
my_plot_config = PerFunctionPlotConfig(
axis_label_override={"spectral": "Wavenumber (cm$^{-1}$)"}
)
with plot_config_context(my_plot_config):
plot_data_overview(DATASET)
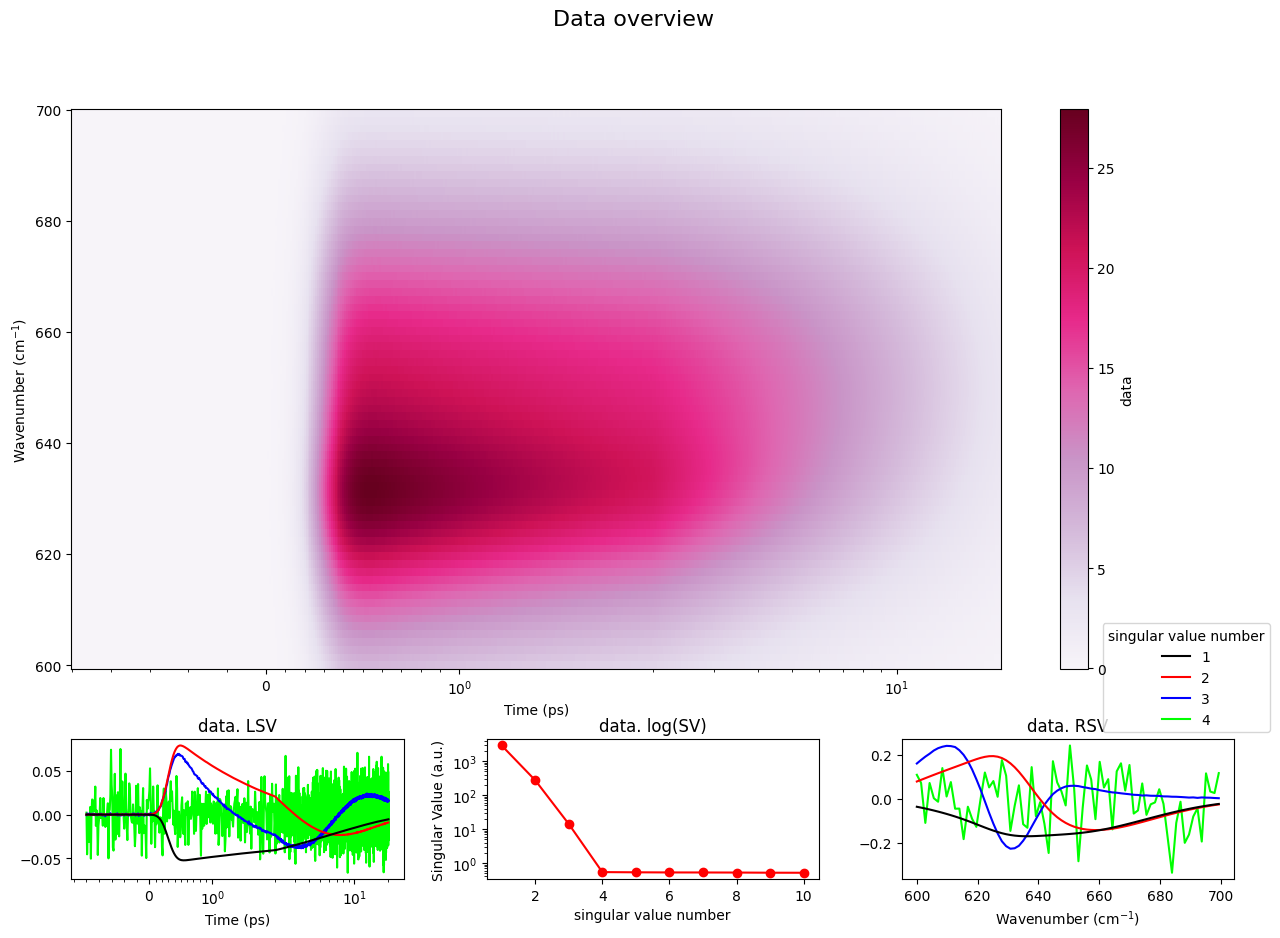
Using the config for you own function#
The plot config isn’t just for our builtin functions but you can also use it with your own custom functions.
Note
For axes label changing to work with you function the function needs to either take them as argument or return them.
from pyglotaran_extras import use_plot_config
import numpy as np
import matplotlib.pyplot as plt
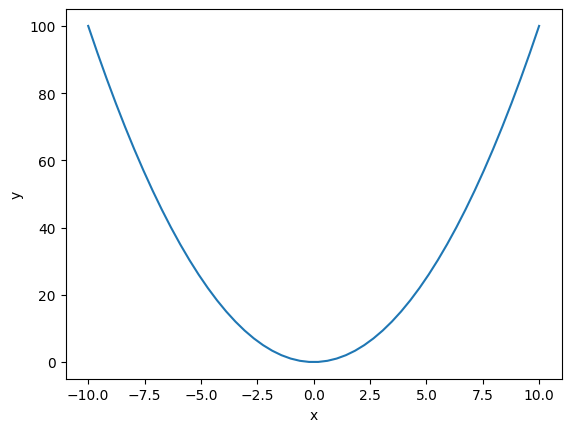
@use_plot_config()
def my_plot(swap_axis=False):
fig, ax = plt.subplots()
ax.set_xlabel("x")
ax.set_ylabel("y")
x = np.linspace(-10,10)
y = x**2
if swap_axis is True:
x,y = y,x
ax.plot(x,y,)
return fig, ax
my_plot();
For quick prototyping of our config we will just use PerFunctionPlotConfig and plot_config_context
from the previous section.
Note
If you aren’t writing documentation you can just export the config to update the json schema and change the file directly including editor support 😅.
my_plot_config = PerFunctionPlotConfig(
axis_label_override={"x":"x-axis","y":"y-axis"},
default_args_override={"swap_axis":True}
)
with plot_config_context(my_plot_config):
my_plot();
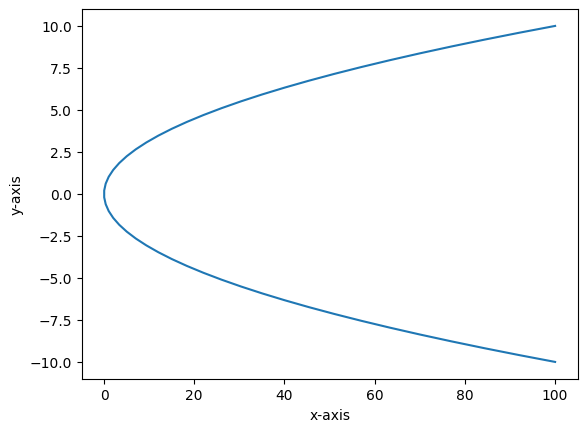
Now that we are happy with the config we can just look at the corresponding yaml and
copy paste it into a new my_plot section inside of the plotting section in the config.
my_plot_config
default_args_override:
swap_axis: true
axis_label_override:
x: x-axis
y: y-axis
Finally we can export the config that is aware of our new function my_plot, which will:
Update the existing config (nothing to do in this case)
Update the schema file to know about
my_plot
So the next time we change something in our config it will be able to autocomplete and lint our the content.
CONFIG.export()
PosixPath('/home/docs/checkouts/readthedocs.org/user_builds/pyglotaran-extras/checkouts/latest/docs/config/project/subproject/pygta_config.yml')
FAQ#
Do I have to use the config?#
No. Using the config is fully optional, however we recommend using it since it reduces the amount of code you need to write and lets anybody reading your analysis focus on the science rather than the python code used to make your plots.
What can the configuration be used for?#
The main goal of the config is to configure plot functions and reduce tedious code duplication like:
Renaming labels of axes
Overriding default values to plot function calls
We try to have sensible default values for our plot functions, but there is no one fits all solution.
Especially since arguments like linthresh (determines the range in which a linlog plot is linear)
are highly dependent on your data.
Thus we give you the power to customize the default values to your projects needs, without having repeating them over and over each time you call a plot function.
Can I still change plot labels myself?#
Yes, the config gets applied when a config enabled plot function is called you can still work with the return figure and axes as you are used to be.
Does using a config mean arguments I pass to a function get ignored?#
No, arguments from the config are only used you don’t pass an argument.
How are config files looked up?#
When you import anything from pyglotaran_extras the location of your project is determined.
This location then is used to look for pygta_config.yaml and pygta_config.yml in the following folders:
Your user home directory
The projects parent folder
The project folder
If you don’t want to include your home folder or a different lookup depth relative to your project
folder you can use CONFIG.rediscover.
If you only want to load the config from a single file you can use CONFIG.load.
Do I need to reload the config after changing a file?#
No, the config keeps track of when each config file was last modified and automatically reloads if needed.
How is determined what config values to use?#
The config follows the locality and specificity principles.
Locality#
Locality here means that the closer the configuration is to the plot function call the higher its importance.
Lets consider the example of the default behavior where configs are looked up in the home directory,
projects parent folder and project folder.
When the global CONFIG instance is loaded it merges the configs in the following order:
Your user home directory
The projects parent folder
The project folder
Where each merge overwrites duplicate values from the config it gets merged into.
Specificity#
For ease of use and reduced duplications, the plot config has a general section
that applies to a plot function with use those arguments or plot labels.
Lets assume that your experimental data use time in picoseconds (ps) and wavelengths in nanometers (nm). Instead of a defining the label override for each function you can simply it to the general section as see above and if a function doesn’t have it defined itself it also gets applied for this function.
CONFIG.plotting.get_function_config("plot_svd")
default_args_override:
linlog: true
use_svd_number: false
linthresh: 2
axis_label_override:
time: Time (ps)
spectral: Wavelength (nm)
data_left_singular_vectors: ''
data_singular_values: Singular Value (a.u.)
data_right_singular_vectors: ''
To demonstrate the effects on the config we will reuse wavenumber_config for the usage example.
with plot_config_context(my_plot_config):
plot_svd_config_wavenumber = CONFIG.plotting.get_function_config("plot_svd")
plot_svd_config_wavenumber
default_args_override:
linlog: true
use_svd_number: false
linthresh: 2
swap_axis: true
axis_label_override:
time: Time (ps)
spectral: Wavelength (nm)
data_left_singular_vectors: ''
data_singular_values: Singular Value (a.u.)
data_right_singular_vectors: ''
x: x-axis
y: y-axis
This change is only valid inside of the plot_config_context and reset afterwards
Which arguments and label are used are defined by the following hierarchy.
Plot function arguments
plot_config_contextGlobal
CONFIG.plottinginstancefunction configGlobal
CONFIG.plottinginstancegeneral
Note
For compound functions like plot_overview which consist of multiple plot config enabled functions
the default_args_override for plot_overview will be passed down to the other functions and
override their usage of own default_args_override config (if arguments are passed they aren’t
default arguments anymore 😅).
Where as axis_label_override for the functions config is first applied to the intermediate plots
and axis_label_override from plot_overview is only applied after that on final plot.
graph TD
A[plot_overview] --> |"default_args_override (plot_overview)"| B[plot_svd]
B --> |"axis_label_override (plot_svd)"| C[intermediate plot]
C --> |"axis_label_override (plot_overview)"| D[final plot]
CONFIG.plotting.get_function_config("plot_svd")
default_args_override:
linlog: true
use_svd_number: false
linthresh: 2
axis_label_override:
time: Time (ps)
spectral: Wavelength (nm)
data_left_singular_vectors: ''
data_singular_values: Singular Value (a.u.)
data_right_singular_vectors: ''
What is the pygta_config.schema.json file for?#
TLDR; It enables autocomplete and error detection in your editor.
JSON-schema is a format that is used to describe data structures including their types in a language agnostic way.